CS460 - Lecture Note
~Nalin Kumar (1611069)
Backpropagation
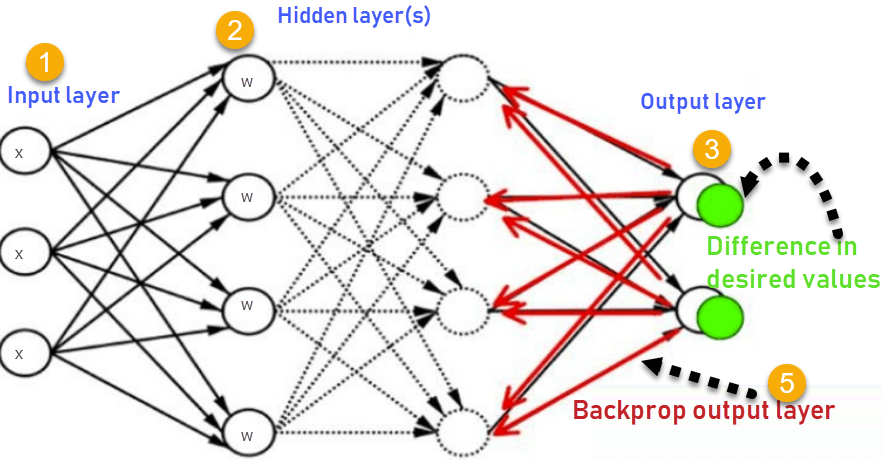
Backpropagation, short for "backward propagation of errors," is an algorithm for supervised learning of artificial neural networks using gradient descent. Given an artificial neural network and an error function, the method calculates the gradient of the error function with respect to the neural network's weights. It is a generalization of the delta rule for perceptrons to multilayer feedforward neural networks.

{kind=link}
What is Backpropagation and how does it work
In machine learning, backpropagation (backprop, BP) is a widely used algorithm for training feedforward neural networks. Generalizations of backpropagation exists for other artificial neural networks (ANNs), and for functions generally. These classes of algorithms are all referred to generically as "backpropagation".The backpropagation algorithm works by computing the gradient of the loss function with respect to each weight by the chain rule, computing the gradient one layer at a time, iterating backward from the last layer to avoid redundant calculations of intermediate terms in the chain rule. In simpler words, it helps to adjust the weights of the neurons so that the result comes closer and closer to the known.
The goal of back propagation algorithm is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs. Here, we will understand the complete scenario of back propagation in neural networks with help of a single training set.
Let us consider a very simple neural network model with two inputs (i1 and i2), which can be real values between 0 and 1, two hidden neurons (h1 and h2), and two output neurons (o1 and o2).

{kind=link}
E1 = MSE(t1, o1)
E2 = MSE(t2, o2), where MSE(x,y) = Mean squared error with truth value = x and predicted value y
We need to minimize E1 and E2 with backpropagation.
The backpropagation algorithm calculates how much the final output values, o1 and o2, are affected by each of the weights. To do this, it calculates partial derivatives, going back from the error function to the neuron that carried a specific weight.
For example, weight w6, going from hidden neuron h1 to output neuron o2, affected our model as follows:
neuron h1 with weight w6 → affects total input of neuron o2 → affects output o2 → affects total errors
Backpropagation goes in the opposite direction:
total errors → affected by output o2 → affected by total input of neuron o2 → affected by neuron h1 with weight w6
The algorithm calculates three derivatives:
- The derivative of total errors with respect to output o2
- The derivative of output o2 with respect to total input of neuron o2
- Total input of neuron o2 with respect to neuron h1 with weight w6
Using the Chain Rule, it is possible to calculate, based on the above three derivatives, what is the optimal value of w6 that minimizes the error function. In other words, what is the “best” weight w6 that will make the neural network most accurate.

Pseudo code for backpropagation [1]
Assign all network inputs and output
Initialize all weights with small random numbers, typically between -1 and 1
repeat
for every pattern in the training set
Present the pattern to the network
// Propagated the input forward through the network:
for each layer in the network
for every node in the layer
1. Calculate the weight sum of the inputs to the node
2. Add the threshold to the sum
3. Calculate the activation for the node
end
end
// Propagate the errors backward through the network
for every node in the output layer
calculate the error signal
end
for all hidden layers
for every node in the layer
1. Calculate the node's signal error
2. Update each node's weight in the network
end
end
// Calculate Global Error
Calculate the Error Function
end
while ((maximum number of iterations < than specified) AND
(Error Function is > than specified))

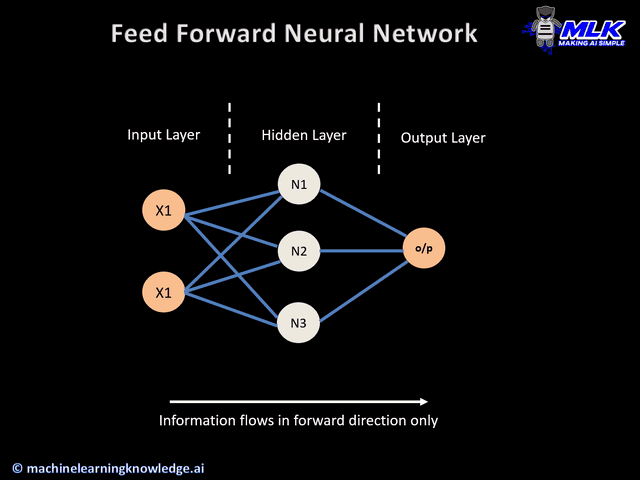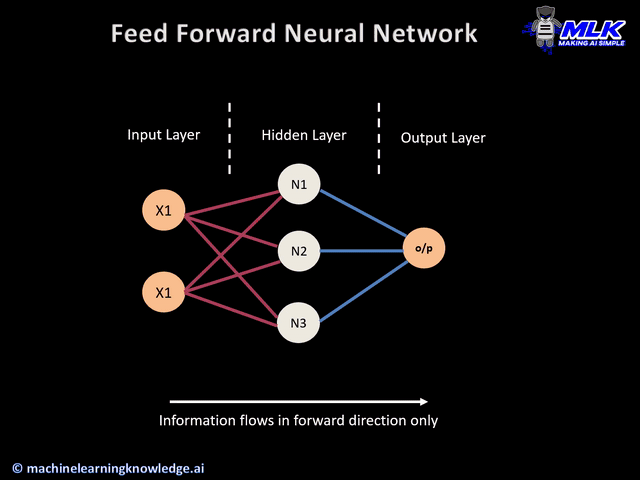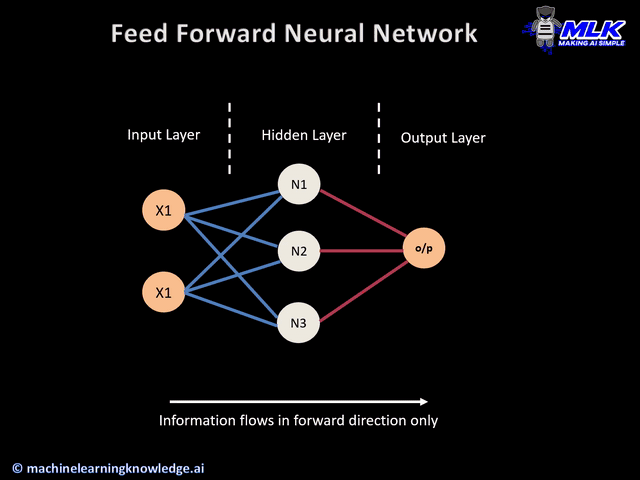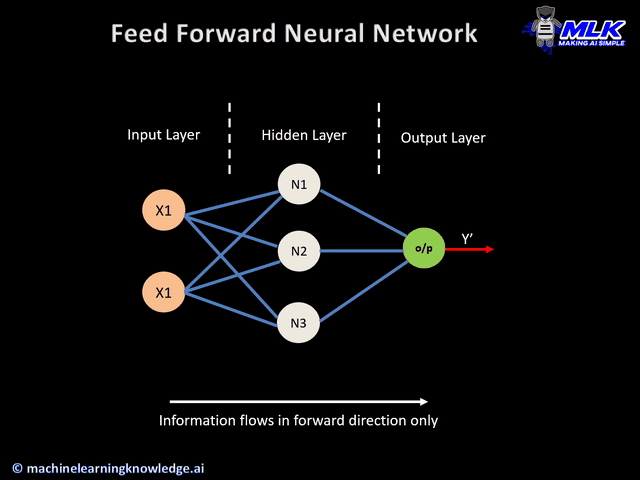{kind=link}
Why Backpropagation
The goal of any supervised learning algorithm is to find a function that best maps a set of inputs to their correct output. The motivation for backpropagation is to train a multi-layered neural network such that it can learn the appropriate internal representations to allow it to learn any arbitrary mapping of input to output.- Backpropagation is fast, simple, easy and accurate to program
- It has no parameters to tune apart from the numbers of input
- It is a flexible method as it does not require prior knowledge about the network
- It does not need any special mention of the features of the function to be learned.
History of Backpropagation
In 1961, the basics concept of continuous backpropagation were derived in the context of control theory by J. Kelly, Henry Arthur, and E. Bryson. In 1962, Stuart Dreyfus published a simpler derivation based only on the chain rule. Bryson and Ho described it as a multi-stage dynamic system optimization method in 1969. The term backpropagation and its general use in neural networks was announced in "Learning representations by back-propagating errors" by Rumelhart, Hinton & Williams (1986, Nature.), then elaborated and popularized in "Learning Internal Representations by Error Propagation" by Rumelhart, Hinton & Williams (1986, Parallel Distributed Processing : Explorations in the Microstructure of Cognition.). In 1993, Wan was the first person to win an international pattern recognition contest with the help of the backpropagation method.[3]Disadvantages of Backpropagation
- Gradient descent with backpropagation is not guaranteed to find the global minimum of the error function, but only a local minimum, i.e., the actual performance of backpropagation on a specific problem is dependent on the input data.
- Backpropagation requires the derivatives of activation functions to be known at network design time.
- Backpropagation can be quite sensitive to noisy data
References
- Backpropagation_UNSW .
- Backpropagation example
- Backpropagation_Wikipedia.
- https://www.elprocus.com/what-is-backpropagation-neural-network-types-and-its-applications/.
- https://www.guru99.com/backpropogation-neural-network.html.