Lecture Notes of 22/09/20 by Adwaith P P(1611009)
Types of machine learning algorithms based on input
How to solve a practical problem?
Before we get into different types of learning, let's see how do we solve a practical problem using machine learning. Generic notion of ML would be solving practical problems. There are two main steps for this
- Gathering data
- Building a statistical model
Data collection is the process of gathering and measuring information from different sources. Gathering data is important step in ML problem. There are four different types of data: text, time-series data, numerical data and categorical data.
Here we build a statistical model based on the same data set using some kind of machine learning algorithm. And this model is not random, it is build in such a way that it would be able to solve this practical problem.
Types of learning
There are different types of learning based on the outputs. For example: regression,classification, ranking etc.Here we discuss about different categories of learning depends on the input. There are four types of learning
- Supervised Learning
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
Supervised Learning
Using supervised learning algorithm, machine learns a function that transform an input to a label based on example input-label pairs.Dataset
In supervised learning we train model using labelled dataset. Dataset can be written as \(\big\{x_i,y_i\big\}_{i=1}^N\). This says there are N-number of labelled examples, where each labelled example would be a collection of feature vector and label. \begin{equation} \Big\{x_i\rightarrow feature\, vector,y_i\rightarrow label\Big\} \end{equation} A feature vector \(x_i\) can have D dimension, where D can be any positive integer. \(x_i\)-feature vector\(\rightarrow\) dimension \((j=1,2,....,D)\). The entire feature vector including dimensions will represent the example. To make it more clear lets consider an example where we take dataset of people and those dataset contains their hight,weight,blood pressure, blood sugar etc. and labels are healthy or not healthy.Dataset \(\rightarrow\) Person
Each example \(x_i\)\(\rightarrow\) represents a particular person
Feature value \(x_i^{(j)}\) \(\rightarrow\) \( (x_i^1\)- height, \( x_i^2\)- weight,\( x_i^3\)- blood sugar,..)
Here similar j value gives similar information. For example \( x_1^1\) and \( x_2^1\) represents height of 1st person and height 2nd person respectively.Labels can be classified in three ways
- Finite set of classes{Spam or not spam, healthy or not healthy or it can be set of numbers also (1,2,3,4,..)}
- A real number
- Complex - {vector,Matrix, Graph}

UnSupervised Learning
In unsupervised Learning the computer is trained with unlabeled data. Here dataset(\(\big\{x_i\}_{i=1}^{N}\)) are just feature vectors and there is no labels attached with it. In this model we input feature vector and the model transforms the vector into some value or vector wich helps you to solve problems.

Examples
- Clustering - clustering algorithm outputs ID of cluster which the example belongs to.
- Dimensionality - In dimensionality reduction algorithm, model transforms input feature vector into feature vector of lower dimension
- Outlier detection - Outlier detection algorithm identifies rare events or items which are significantly different from the dataset.
Semi-supervised Learning
Semi-supervised learning dataset contains both unlabelled and labelled(\(\big\{x_j\}\)+\(\big\{x_i,y_i\big\}\)) and goal of this model is same as supervised learning.
How datas are using in semi-supervised learning?- This question answers why does this model works properly. First we use unsupervised learning algorithm to cluster the similar data then use the supervised learning to the existing data to label the rest of the unlabeled data.
Which model is better among these three types of learning?- We select the type of model according to the situation. If we have enough labelled data then we go for supervised learning and semi-supervised learning is used when we have less labelled data and more unlabelled data. Usually supervised learning is better than other two and semi supervised is better than unsupervised.
Supervised\(>\)Semi-supervised\(>\)Un-supervised
There is a point to be noted. The above mentioned is true in general but if we have suppose 400 labelled data for supervised and 300 labelled and 5000 unlabelled data for semi-supervised, then it is not easy to say which model works better.
Reinforcement Learning
In reinforcement learning algorithm we train the machine to make a sequence of decisions. Machine continuously learns from the environment in an iterative fashion and it interact with the enviroment to take actions that would maximize the reward. In this method input is state(feature vector) and model or policy outputs action to get maximum reward. Here goal is long term.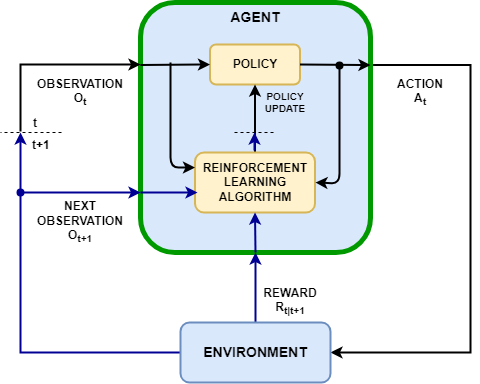
Examples - Game playing, Robotics, Chess