Lecture Notes of 23/09/20
Supervised Learning
Supervised Machine Learning is where we give input(X) and output(Y) variables to an algorithm which approximates a mapping function between these from the training data so that when we give a new input data, it can predict the output variables for that data.
The Data in supervised machine learning consists of :
- Input : It could inlcude numbers, pictures, emails, measurements etc.
- Output : These could be numbers, labels (like spam/not-spam), vectors(like coordinates of a bounding box), sequences etc.
Now let us look at an example where supervised machine learning is used. One of the popular areas it is used is for spam detection in emails. It is used to categorize emails as either spam or not spam.
-
The input dataset consists of emails where each email consists of words and phrases. However, these arent in machine readable format. So we need to convert it into machine readable format. There are several ways to do this. We will look at a fairly simple technique called Bag of Words.
Bag of Words Model is a simple representation used in Natural Language Processing (NLP is a field of study concerned with processing and analysing large amounts of natural language data. Some of the challenges in NLP are translation, speech-recongnition etc.), where a text (in our case content of email) is represented as a multiset of words. Bag of words also has several ways of implementation. One way is assigning a digit 1 if a particular word is present and 0 if not. So assume we have a set of 5000 different words in a particular order. If our email has the first word in this set, then we assign it 1 otherwise 0. So our final result given an email would look like this for example - [10110......01011110]. So, given an email, our Feature Vector would be a ordered set of 5000 element consisting of zeros and ones.
-
The output for this spam-detection model would be labels - 'Spam' or 'Not-Spam'. Given an email as input, the model should return us either one of these labels.
- For the training part, lets take 10000 emails. So we have 10000 feature vectors where each feature vector has a dimension of 5000. And we also have labels for each of these feature vector.
-
The model we will be using in this particular problem will be an SVM. Support Vector Machines are supervised machine learning models which constructs a hyperplane or a set of hyperplanes in a finite or infinite dimensional space which can be used for classification or regression purposes[1].. Basically, given some training data, the SVM will produce a hyperplane which has the largest separation from the training data points. The term Hyperplane used earlier refers to a subspace who dimension is one less than the ambient space we are working in. SVM is simply an optimization problem that tries to find a separating hyperplane with as large a margin as possible. It can be written as a constrained optimization problem as follows:
$$ \mbox{min}_{(w,b)} \mbox{ } \frac{1}{\gamma(w,b)} $$ $$ \mbox{subj. to } y_n(w \cdot x_n + b) \ge 1 $$Here \(\gamma \) denotes the margin which we have to maximize (therefore, in the above equations we are minimising the the reciprocal of the margin), subject to the constraint that all training examples are correctly classified. Here we have put the condition that the classification of each point to be greater than or equal to 1. However, this can be any other posistive constant. The constant just ensures that there is a separation between the two classes.
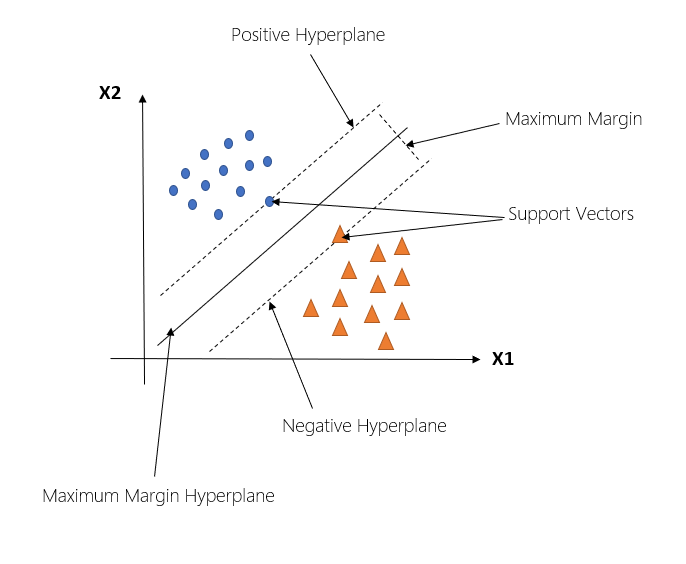
Fig. Hyperplane separating the two classes (Image Credits: Support Vector Machine Beginners Guide , medium.com) In our given problem, the hyperplane will be the line that separates the spam and not-spam data points most suitably. It will give the most optimum value of the parameters - w and b. After the end of training, the SVM will be able to produce a very accurate hyperplane which separates the 10k training samples into two regions - spam and not-spam.
- Now we can test our model. If we give an email as an input, it would be first converted into a feature vector of 5000 dimension and then depending on which side of the hyperplane the given datapoint lies, it will be labelled as either spam or not-spam.
Note :
The above optimization problem works only if the data is linearly separable. If not, there would be no suitable set of parameters w and b which can simultaneously satisfy all the constraints. In such cases, people will either work with a slightly different model known as soft-margin SVM or move on to non-linear hyperplanes depending on which is suitable for the problem.Let's summarise the steps involved in Supervised Machine Learning :
- Getting the Data.
- Converting into feature vectors.
- Generating the Model.
- Predicting the output for a new input data.
The type of decision boundary we want will depend on the following factors:
- The type of classification algorithm we are using as each one will have a different decision boundary form.
- Decision boundary could be implicit or explicit.
- Decision boundary also determines the accuracy.
- Decision boundary form (Example - linear/non-linear)
- Speed - this is the rate at which the model is built.
- Prediction time - time taken to predict the output for an input data.
- Why does the model work on new data? Because we assume that the new data will be similiar to old data. This is the reason why we need more training samples. More are the samples, the better hyperplane will be formed by the model.
References
- Support-Vector Machine.
- A Course in Machine Learning by Hal Daume .